【SparkSQL 】扩展 ---- 数据清洗:缺失值处理
本文共 3036 字,大约阅读时间需要 10 分钟。
【SparkSQL 】扩展 ---- 数据清洗:缺失值处理
目录:
一、什么是缺失值
1.、缺失值的含义
一个值本身的含义是这个值不存在,则称之为缺失值,也就是说这个值本身代表着缺失,或者说这个值本身无意义,比如null、空字符串…
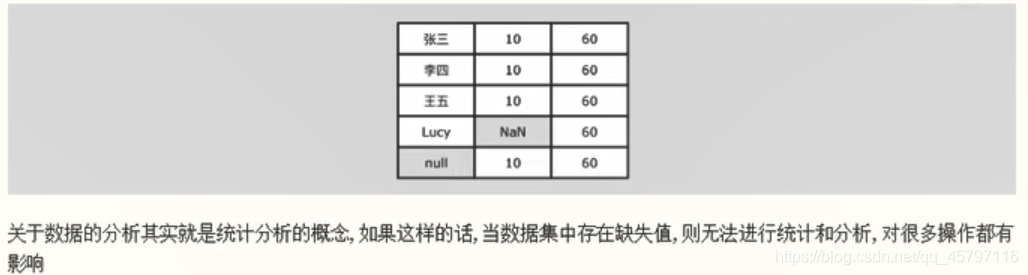
null —> 对象为空
NAN —> Not A Number
2.、缺失值的产生
-
从业务系统中来
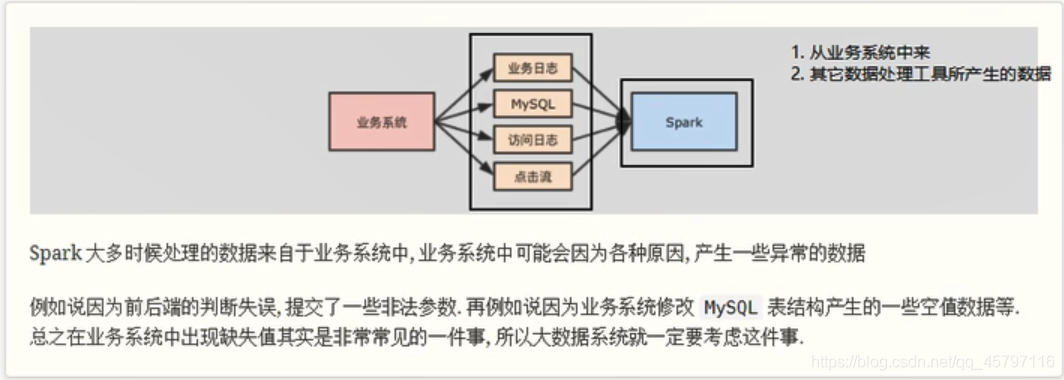
-
其他数据处理工具所产生的数据
3.、缺失值的类型

二、DataFrameNaFunctions 缺失值处理框架
1.当数据集中出现缺失值的时候,大致有两种处理方式
- 一个是丢弃
- 一个是替换为某值
2.DataFrameMaFunctions中包含一系列针对空值数据的方案:
DataFraneNaFunctions.drop可以在当某行中包含null或NaN的时候丢弃此行DataFraneNaFunctions.fill可以在格null和NoN充为其它值DataFrameNaFuncttons.replace可以把null或NaN管换为其它值,但是和 fill 略有一些不同,这个方法针对值来进行替换
三、NaN 、null 缺失值
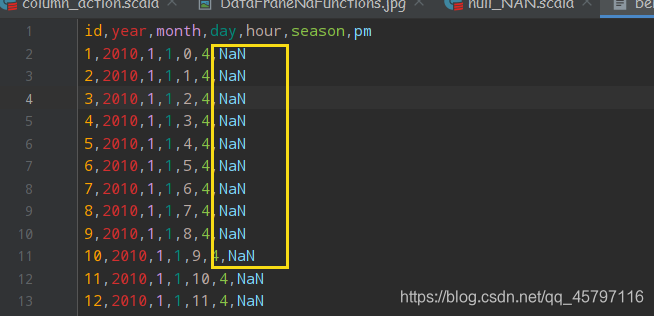
- 读取文件
// 方式一 //2.1 自动判断数据类型读取 val ds = spark.read .option("header",true) .option("inferSchema",true) .csv("dataset/beijing_pm_nan.csv") 缺点: 在推断的时候可能会将数字类型的列中的NaN值推断为字符串类型 // 方式二//2.2 直接读取字符串,在后续过程中使用map算子转换数据类型spark.read .option("header",true) .csv() .map(row => row....) // 方式三// 2.3 指定Schema,不需要推断 val schema = StructType( List( StructField("id", LongType), StructField("year", IntegerType), StructField("month", IntegerType), StructField("day", IntegerType), StructField("hour", IntegerType), StructField("season", IntegerType), StructField("pm", DoubleType) ) ) val df = spark.read .option("header", true) .schema(schema) .csv("dataset/beijing_pm_nan.csv") 1.丢弃
// 4.1 丢弃 // 2019,12,12,NaN // 规则: // 1.all --- 该行数据都是NaN时才进行删除 df.na.drop("all").show() // 2.any --- 只要有一个数据为NaN就进行删除 df.na.drop("any").show() // 默认的就是any // 3.针对于某些列的特殊规则 df.na.drop("any", List("year", "month", "day", "hour")).show() // any 只作用于List中的列 - all — 该行数据都是NaN时才进行删除
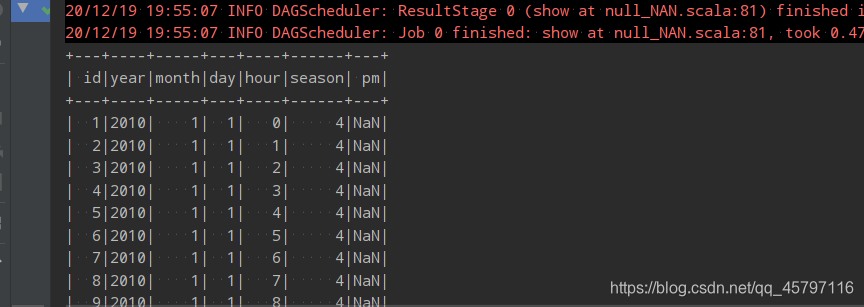
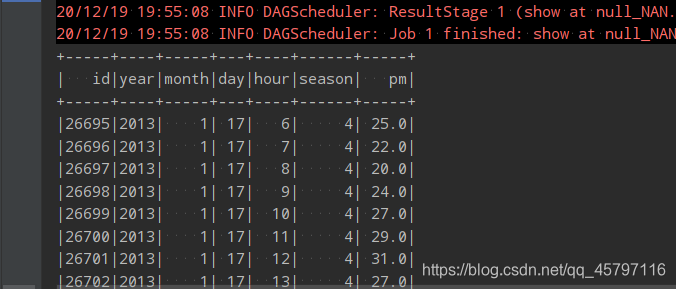
- any — 只要有一个数据为NaN就进行删除,相比于all的结果来说,当记录中只要一个字段的数据为NaN值,整条记录就会被删除。
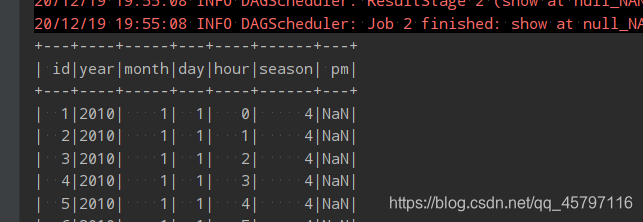
- 针对于某些列的特殊规则,相比于上面any的结果,下面的结果保留了pm列为NaN的记录,原因在于本方法处理时,针对了特定的列,并没有把pm列放入。

2.填充替换
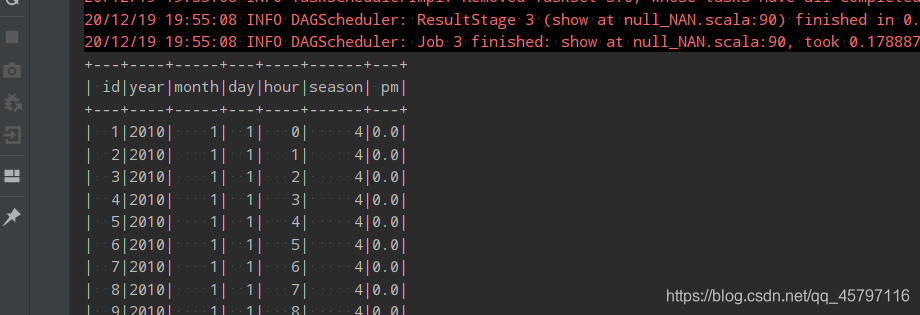
// 4.2 填充 // 规则: // 1.针对所有列数据进行默认值填充 df.na.fill(0).show() // 2.针对特定列进行填充 df.na.fill(0, List("year", "month")).show() - 针对所有列数据进行默认值填充
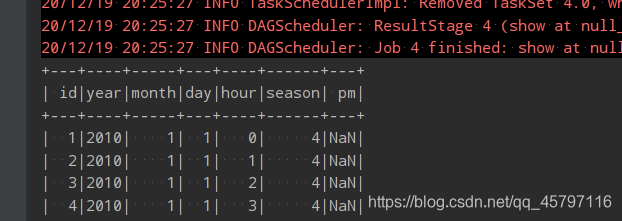
- 针对特定列进行填充
四、字符串缺失值
案例:
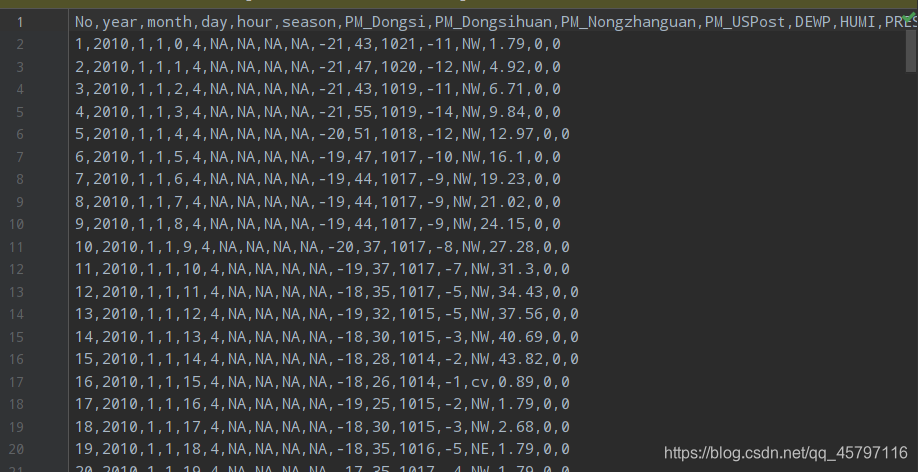
// 读取原始数据集 val df = spark.read .option("header", true) .option("interSchema", true) .csv("dataset/BeijingPM20100101_20151231.csv") 通过对原始数据集的读取,我们可以发现在自动推断类型的时候将某些字段以StringType的形式读取,所以在后续的处理中就是针对字符串缺失值。

1.丢弃
// 1.丢弃df.where('PM_Dongsi =!= "NA").show() - 直接丢弃PM_Dongsi列值为NA的记录

2.替换
// 2.替换// select name,age,case // when ... then ... // ... // else import org.apache.spark.sql.functions._ df.select( 'No as "id", 'year, 'month, 'day, 'hour, 'season, when('PM_Dongsi === "NA", Double.NaN) .otherwise('PM_Dongsi cast DoubleType) .as("pm") ).show() data_na.na.fill(0,List("pm")).show() - 读取数据的时候对
PM_Dongsi列的值进行判定,如果为字符串型空值,将其转换为好处理的Double.NaN类型,后续采用空值处理,否则转换其数据类型为DoubleType。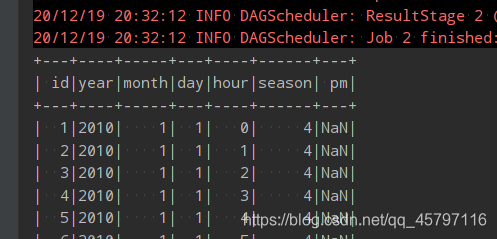
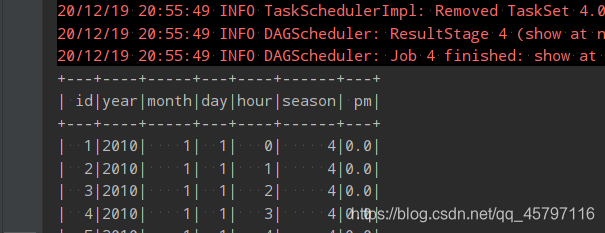
3.用replace将特殊值替换为好处理的值
// 使用replace将特殊值替换为好处理的值// 注意:在转换时,原类型必须和转换后的类型保持一致!df.na.replace("PM_Dongsi", Map("NA" -> "NaN", "NULL" -> "null")).show() - 这里使用replace将字符串的NA、null进行了替换,虽然形式匹配,但是依旧是字符串型的数据,还需要再进行类型转换
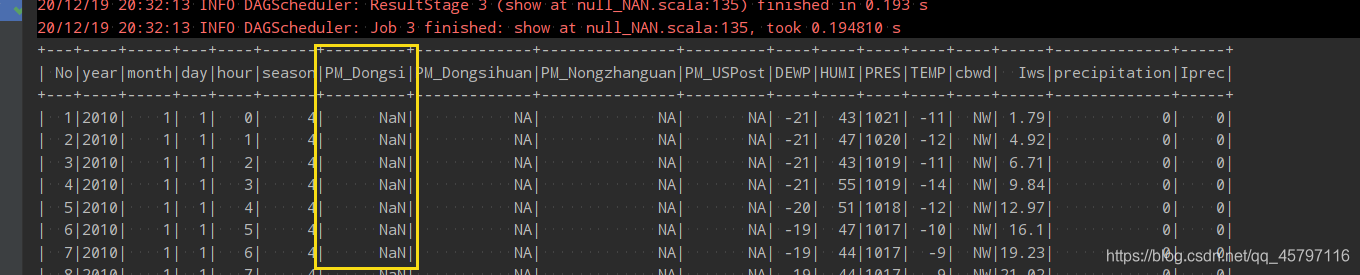
val data_NA = df.na.replace("PM_Dongsi", Map("NA" -> "NaN", "NULL" -> "null")) data_NA.show() // 再次转换数据类型为DoubleType val type_trs = data_NA.select('NO.as("id"),'year,'month,'day,'season,'PM_Dongsi.cast(DoubleType) ) type_trs.show() println(type_trs.schema) // 填充空值 type_trs.na.fill(0).show() 
转载地址:http://zzeq.baihongyu.com/
你可能感兴趣的文章